本文内容基于 Andrej Karpathy 的视频 State of GPT,并加入了个人理解,进行总结。
该部分的主题是how to train your GPT assistants, 在chatGPT 的语境中,Assistant 特指能回答问题,像助手一样可以帮我们做很多事。
0. GPT训练的四个阶段

目前我们能够使用到的chatGPT 都是RLFH 模型,该模型的训练可以分为3个阶段
- pretraining 预训练
- Supervised finetuning 监督微调
- Reinforcement Learning from Human Feedback, 包括reward modeling 和Reinforcement Learning, 因为reward modeling 不能独立起作用,也不能独立部署,必须Reinforcement Learning结合使用,所以把它们归类为一个阶段。
在以上每个阶段中,都有各自训练需要的数据集、算法、和训练输出结果
1. pre-training 预训练
pre-trainin 预训练阶段是一切的起点,它需要最多的数据,最多的计算资源GPU,最长的训练时间。
总的特点如下
- 大规模数据:预训练使用的大规模数据集包含了来自互联网的各种文本,这些数据集规模庞大,通常包含数十亿甚至数百亿个token。
- 无监督学习:预训练通常采用无监督学习方法,即不需要人为标注的数据。模型通过预测文本中的下一词(或下一个token)来学习语言结构和模式。
- 通用性:预训练模型具有通用性,因为它并没有针对特定任务进行优化,而是广泛地学习各种语言模式。这种通用性使得模型可以适应多种下游任务。
1.1 Dataset
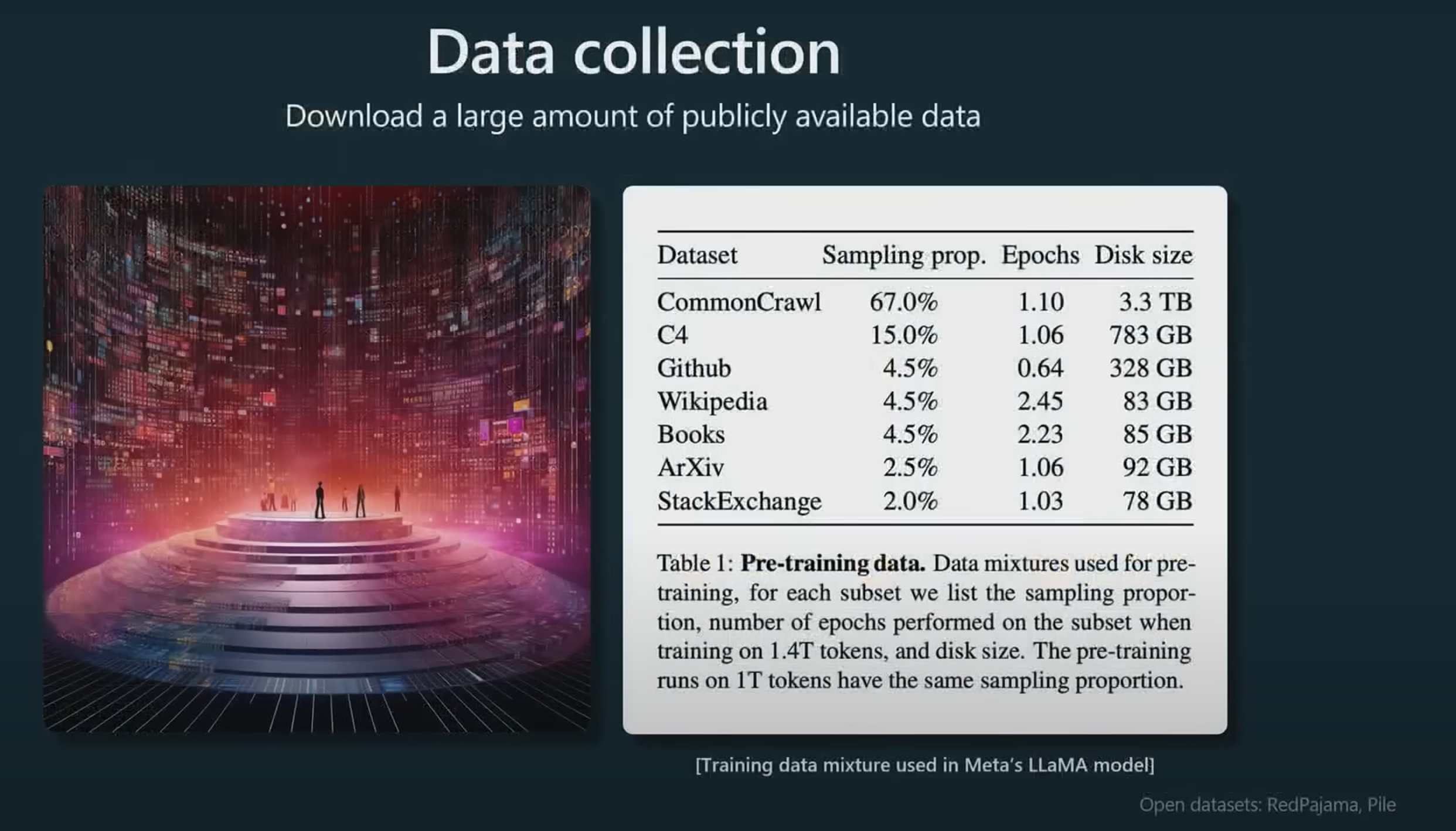
预训练使用的大规模数据集包含了来自互联网的各种文本,这些数据集规模庞大,不过目前chatGPT 没有公开具体的数据, 上图是meta 开源的LLaMA的训练数据集
- 67.0%的Common Crawl,也就是常规网络爬取的数据集,这部分数据集的特点是内容涉及的类型很全面,但是因为内容可能是任何人写的,质量一般偏低,也会包含大量不相关,例如广告、导航条、版权声明等。
- 15.0%是C4数据集 (Colossal Clean Crawled Corpus, “庞大的清洁语料库”),这个数据集包含了大量的网页文本,这些文本已经过清理,移除了广告、重复内容、非英语文本、和其他不适合训练的元素。这个数据集的目标是提供一个大规模、高质量、多样性强的英语文本数据集,以支持自然语言处理任务。尽管C4经过清理,但仍然包含了来自互联网的各种文本,因此可能包含一些质量不高的信息的信息。
- 剩余18%的训练数据来源主要是来自Github、维基百科、书籍、Arxiv论文、交易所等, 可以认为是高质量的数据。
这些训练数据有以下特点
- 规模庞大:训练数据的数量非常大,包含数十亿条文本记录。这种大规模的数据量帮助模型学会语言的复杂性和细微差别。
- 多样性:训练数据涵盖了广泛的主题和领域,包括科学、艺术、历史、文学、技术、日常生活等。这种多样性使得模型能够应对各种类型的问题和对话。
- 广泛覆盖:涵盖了从基础知识到专业知识的广泛范围,使得模型在回答问题时既能处理简单的日常问题,也能应对复杂的专业问题。
- . 开放获取:所有数据都来自公开可获取的资源,没有使用私人或受保护的数据,确保了数据的合法性和道德性。
根据以上特点,可以总结认为像chatGPT 这样的LLM, 学习了人类在互联网上发表过所有知识。不过由于高质量的数据只占18%, 如果你想获取高质量的回答,所以你需要一些chatGPT 沟通的技巧, 即prompt 技巧,才能获取高质量的回答。
1.2 preprocess dataset-Tokenization
针对从互联网上获取到的大量数据,chatGPT 并不是直接拿来训练,而是要经过tokenization 标记化,将文本转换成模型可以理解的整数序列。
1.2.1 什么是Tokenization?
Tokenization是将文本拆分成较小的单元(称为tokens)的过程。这些tokens可以是单词、子词、字符或其他文本片段,,并将其映射到特定的标记或整数的过程。

从图中可以看出,GPT 并不是直接使用从互联网上获取的原始数据进行训练, 而是先讲数据分解成token,再将token 转化成整数数列。最终进入到神经网络/Transformer 进行训练的是这些整数数列。
以下Tokenization的步骤:
文本清理:在进行Tokenization之前,文本可能需要清理,比如去掉多余的空格、标点符号的处理等。这一步骤视具体应用而定。
拆分文本:将文本拆分成tokens。例如,对于句子“ChatGPT is great.”,可以拆分为“ChatGPT”、“is”和“great”。
子词级别的Tokenization:现代语言模型(如GPT-3)通常使用子词(subword)级别的Tokenization,如Byte Pair Encoding(BPE)或WordPiece。这些方法可以将罕见词分解为更常见的子词片段。例如,单词“unhappiness”可以分解为“un”、“happiness”或进一步分解为“un”、“happi”、“ness”。
分配唯一ID:每个token被分配一个唯一的整数ID,模型内部使用这些ID而不是直接使用文本。例如,“ChatGPT”可能被分配ID 12345,“is”被分配ID 6789,依此类推。
1.2.2什么是token
token 在自然语言处理(NLP)中扮演着核心角色,尤其是在训练像ChatGPT这样的大型语言模型时,token是模型训练和生成文本的基本单位。 在英语预料中,它可以是是一个词、也可以是一部分词、或者一个字符(虽然演讲中示例对token 的举例基本是都是完整的单词)
那么这里就要思考,为什么不用完整的单词训练呢,既简单又直接。
- 词汇表大小和稀疏性问题
使用完整单词进行训练的一个主要问题是词汇表的大小。英语和其他语言中的词汇量非常庞大,尤其是当考虑到新词、专有名词、不同的词形变化(如复数形式、时态等)时,词汇表的规模可能会变得非常大。- 大词汇表问题:一个庞大的词汇表意味着模型需要处理更多的单词,这不仅增加了模型的复杂性,还会显著增加训练和运行模型所需的资源(如内存和计算时间)。
- 稀疏性问题:当词汇表很大时,很多单词在训练数据中出现的频率可能非常低,导致数据稀疏。稀疏性问题会降低模型对这些单词的学习效率,影响模型的性能和泛化能力。
- 处理未知词汇的能力
直接使用完整单词进行训练面临的另一个挑战是如何处理训练数据中未出现过的单词(即未知词汇或OOV问题)。- 未知词汇(OOV)问题:在新的文本中经常会出现训练数据中未见过的单词。如果模型只学习到了完整单词,那么它很难处理这些未知词汇。
- 泛化能力:通过使用子词(如词干、前缀、后缀等)或更小的单元,模型可以更好地泛化到未见过的单词。例如,通过识别“un-”和“-able”这样的前后缀,模型可以推断出“unbelievable”等单词的含义,即使这个词在训练数据中没有直接出现过。
- 训练效率和计算资源
分词还可以帮助提高训练效率和减少对计算资源的需求。- 减少参数数量:较小的词汇表可以减少模型的参数数量,降低过拟合的风险,同时提高模型的训练速度和推理速度。
- 内存和存储优化:使用更小的词汇表意味着可以更高效地使用内存和存储资源,尤其是在嵌入层中。
- 适应多样化的语言现象
语言中存在大量的变体和创新,直接使用完整单词可能难以适应这些变化。- 词形变化:在许多语言中,单词可以有多种形式。使用基于规则或统计的分词方法可以帮助模型理解不同词形之间的关联,提高模型对语言变化的适应能力。
- 新词创造和网络语言:新词和网络流行语的出现是常态。分词系统可以通过更新词库或调整分词算法来适应这些变化。
1.3 Unsupervised Learning-无监督学习
预训练采用无监督学习方法,即不需要人为标注的数据。模型通过预测文本中的下一词(或下一个token)来学习语言结构和模式。
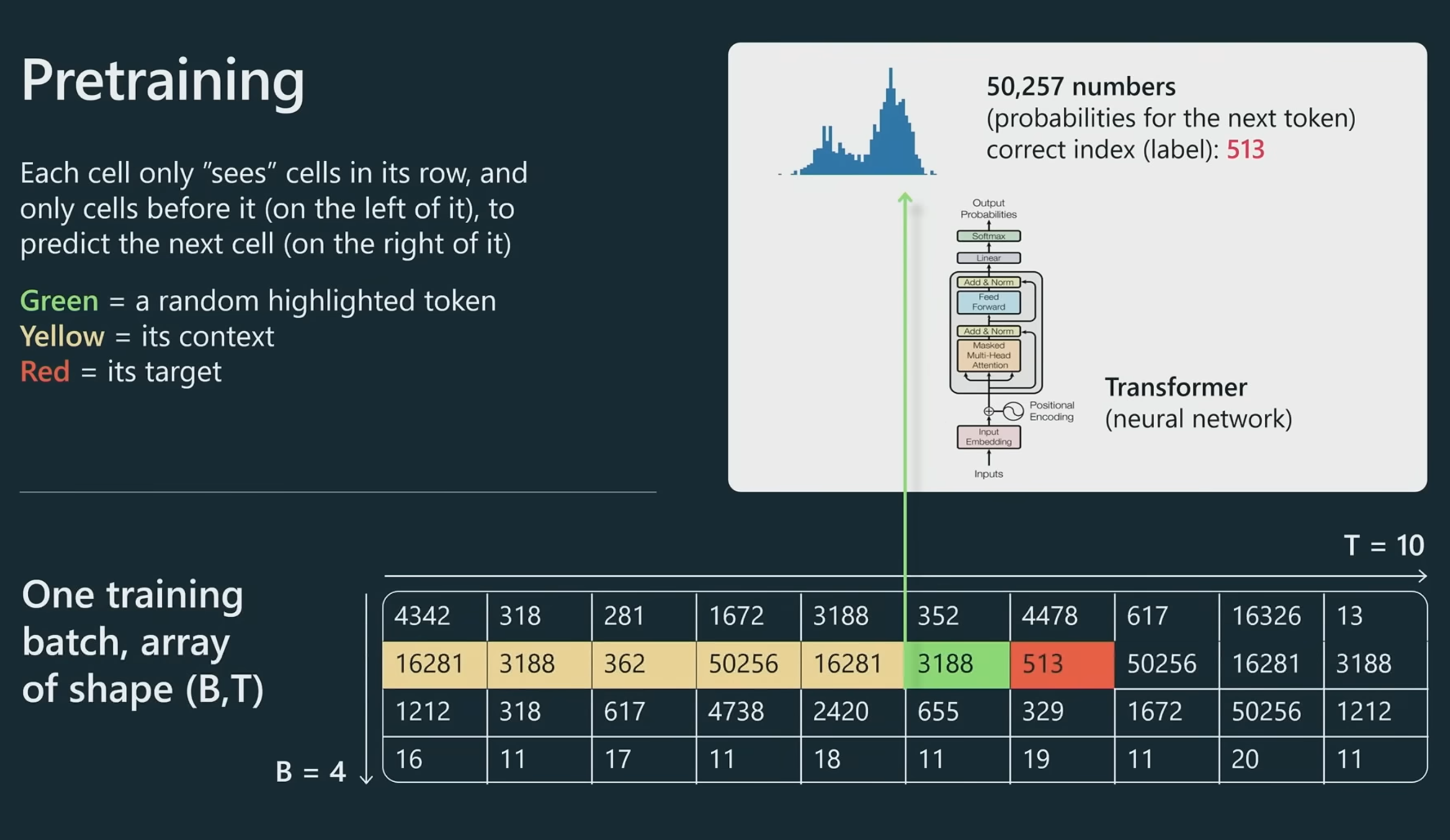
数据会以批次为单位, 输入到Transformer中进行训练,其训练过程就是不断让模型根据前面已经的内容(黄色部分),去猜测当前token(绿色部分)的下一个词是什么(红色部分), 如果猜测的结果和实际情况不一致,则要调整模型,直至结果一致。
猜测的过程是基于概率进行的。
如果猜错了,那距离正确答案又多远,这就是损失函数的概念。低损失意味着更高的预测正确概率
1.3 base model
预训练完成后会得到一个base model ,因为它并没有针对特定任务进行优化,而是广泛地学习各种语言模式。这种通用性使得模型可以适应多种下游任务。
1.3.1 base model are not assistant
这句话的含义是base model 并不能回答问题。
预训练阶段得到的base model 只是一个文档生成器, 只会根据你输入的内容去预测下一个单词,并不会回答你的问题,所以还起不到assistant 助手 的作用。 如图中,base model 并不会按照你的要求写诗,知识生成相似的内容。
what is the capital of France?
再例如针对以上问题,base model 并不会回答问题,给出“Paris”, 而是会续写内容, 给出以下可能的答案
what is France’s largest city?
what is France’s population?
what is the currency of France?
1.4 如何让 base model 回答问题
1.4.1 few-shot Learning
Few-shot Learning:指的一种在给模型提供少量示例的情况下让其学习新任务的方法。Few-shot 可以分为零样本学习(zero-shot learning)、一样本学习(one-shot learning)和小样本学习(few-shot learning)。
原理:模型在大规模语料上进行预训练,学到了广泛的语言知识和基本任务能力。在新任务上,通过提供少量的示例(输入-输出对),模型可以从中推断出该任务的模式和要求。
few-shot 之所以起作用,是把问题伪装成了一个文档中缺失的内容,让base model 通过完成文档的能力把它补全。但是这一过程非常不稳定, 在实践中总体效果一般。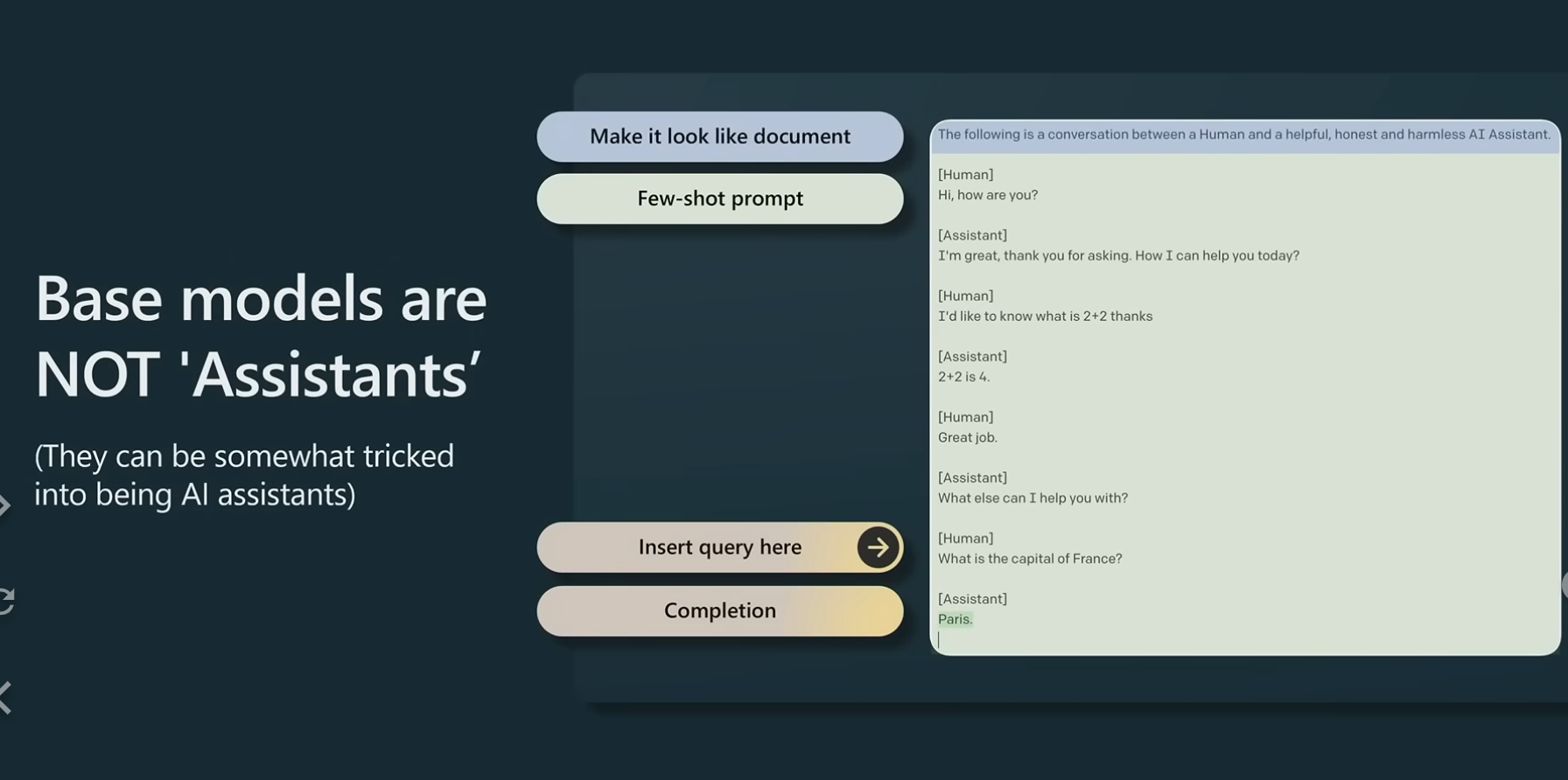
1.4.2 Supervised finetuning
指在base model 的基础上,使用带有标签的数据集对模型进行进一步训练,以提高其在特定任务上的表现。
1.4.3 few-shot vs Supervised finetuning
- Few-shot Learning:
- 优点:无需大量标注数据,适应新任务快速。
- 缺点:在任务复杂或示例较少时,效果可能不如监督微调。
- 监督微调:
- 优点:在有足够标注数据时,能够显著提升模型性能。
- 缺点:需要大量标注数据,成本较高。
2. Supervised finetuning stage 微调
指在base model 的基础上,使用带有标签的数据集对模型进行进一步训练,以提高其在特定任务上的表现。
2.1 Dataset
相比pre-training 预训练阶段,Supervised finetuning 监督微调阶段使用少量但高质量的数据集。
这些数据集包含了成对的输入和期望输出,例如问题与答案(Q&A)、命令与响应、或者其他相关任务的配对。
这些数据通常通过以下方式获得:
- 人工标注:雇佣标注人员根据预设的指导文档(labeling documentation)来创建数据。标注人员可能会根据给定的指令编写问题的答案,或者评估和选择模型生成的候选回答。
- 众包平台:使用众包服务(如Amazon Mechanical Turk)来收集和标注数据。这种方式可以快速且成本相对较低地获得大量标注数据
- 合作伙伴:与学术机构、研究组织或其他公司合作,共享或共同创建数据集。
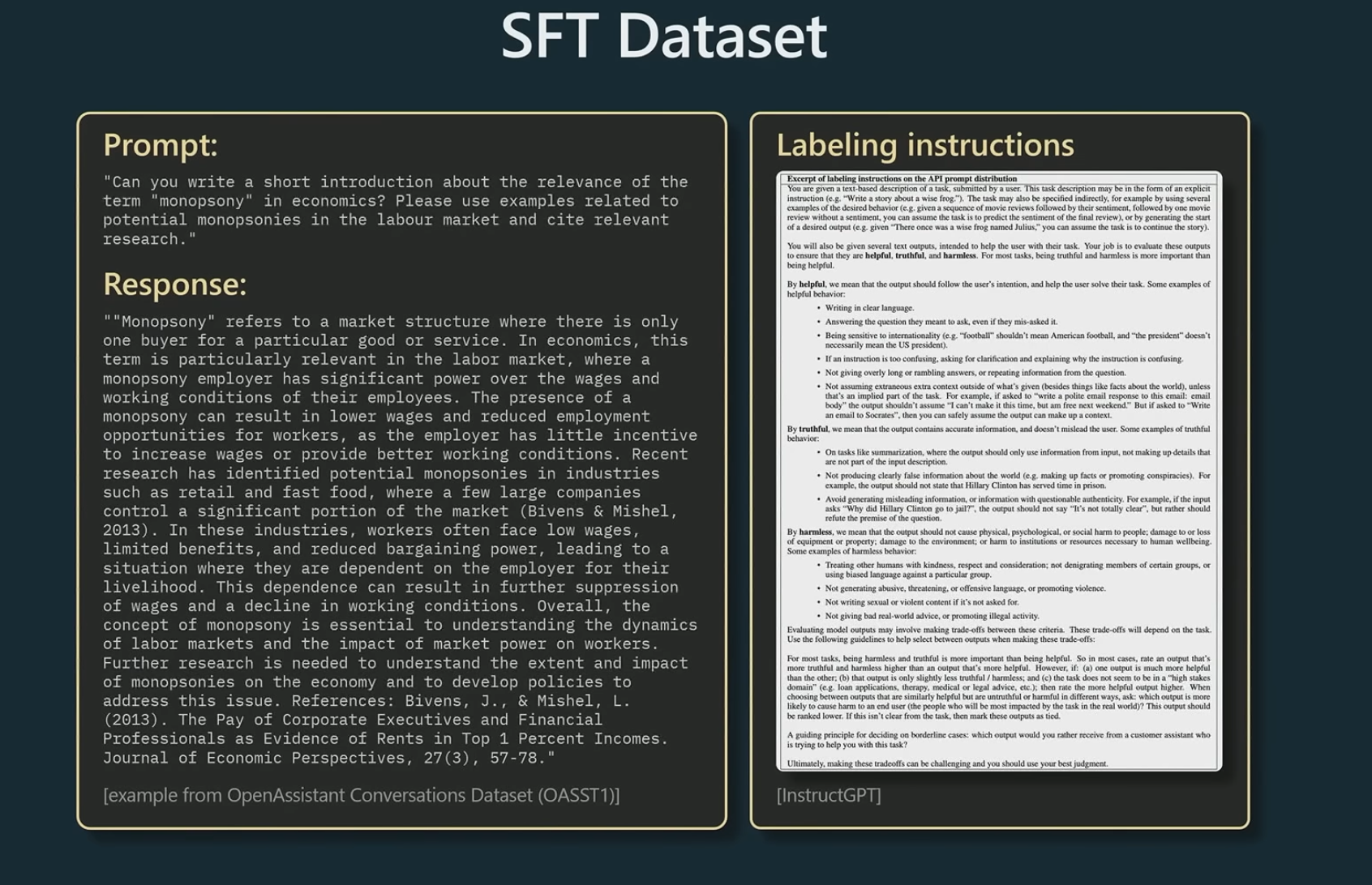
2.2 SFT model
SFT model 已经是一个可以回答问题的assistant
2.4 Pre-training vs fine tuning
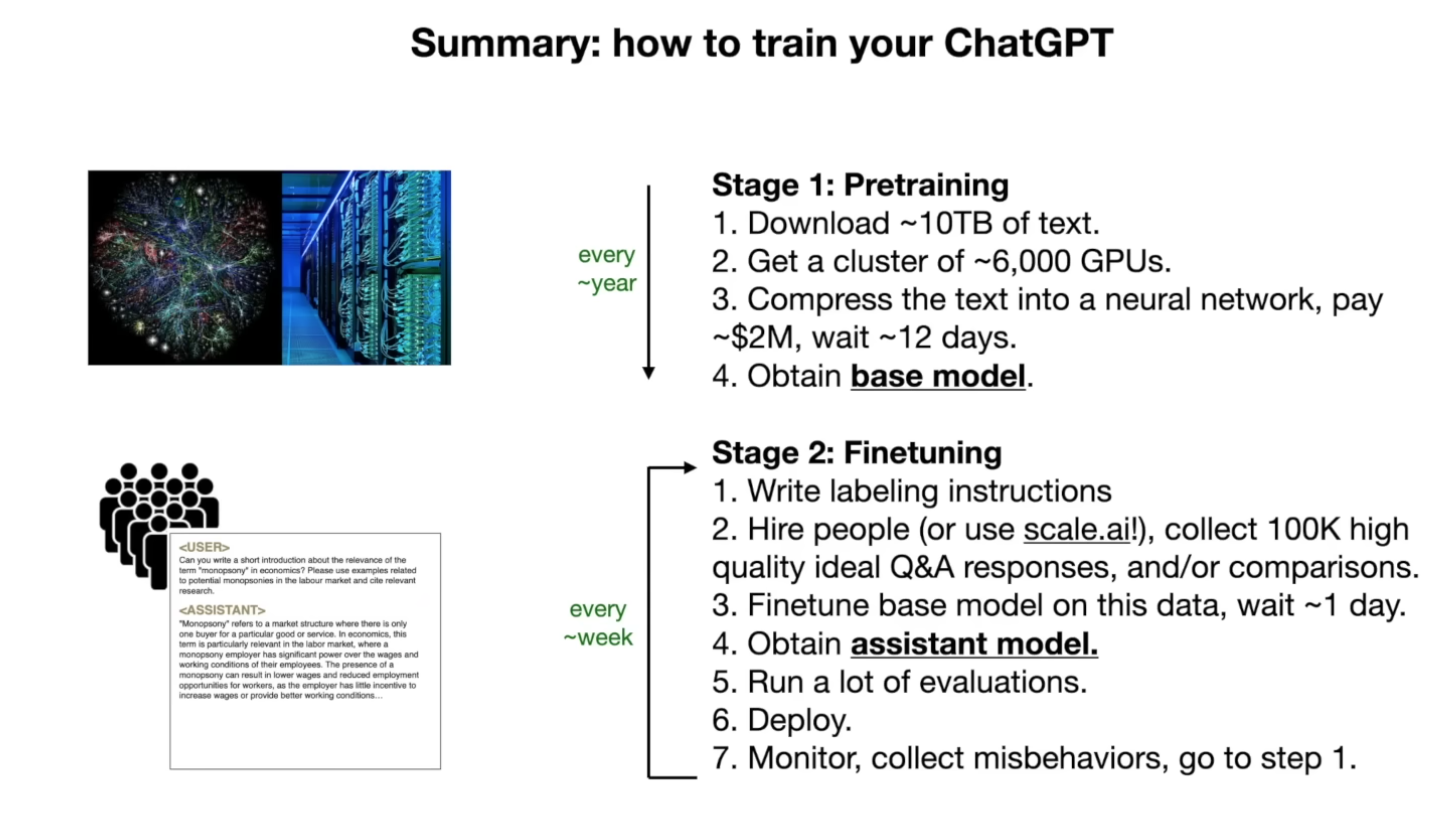
以下是预训练(Pre-training)和微调(Fine-tuning)两个阶段的对比表格,从目标、数据集、过程、成本和迭代与改进五个方面进行总结:
| 特征 | 预训练(Pre-training) | 微调(Fine-tuning) |
|---|---|---|
| 目标 | 学习广泛的语言知识和互联网信息,不专注于特定任务。 | 调整预训练模型以适应特定任务或应用场景。 |
| 数据集 | 来自互联网的大规模、多样化文本数据,可能包含多种语言和主题。 | 较小但高质量的特定任务相关数据集,如问答对、标注文本等。 |
| 过程 | 通过预测文本序列中的下一个词进行训练,使用大规模数据集进行广泛学习。 | 在预训练模型的基础上,使用特定任务的数据集进行额外训练。 |
| 成本 | 高,需要大量计算资源(如GPU集群)和时间,成本可能高达数百万至数十亿美元。 | 相对较低,主要涉及数据标注和模型调整,计算资源需求较小。 |
| 迭代和改进 | 通常在大型公司或研究机构中进行,可能每年或几个月进行一次,取决于资源和需求。 | 可以频繁进行,根据模型表现和用户反馈不断优化模型。 |
3. RLHF
Reinforcement Learning from Human Feedback
根据人类反馈进行强化学习
这个阶段包含两个步骤,
3.1.1 Dataset- comparisons
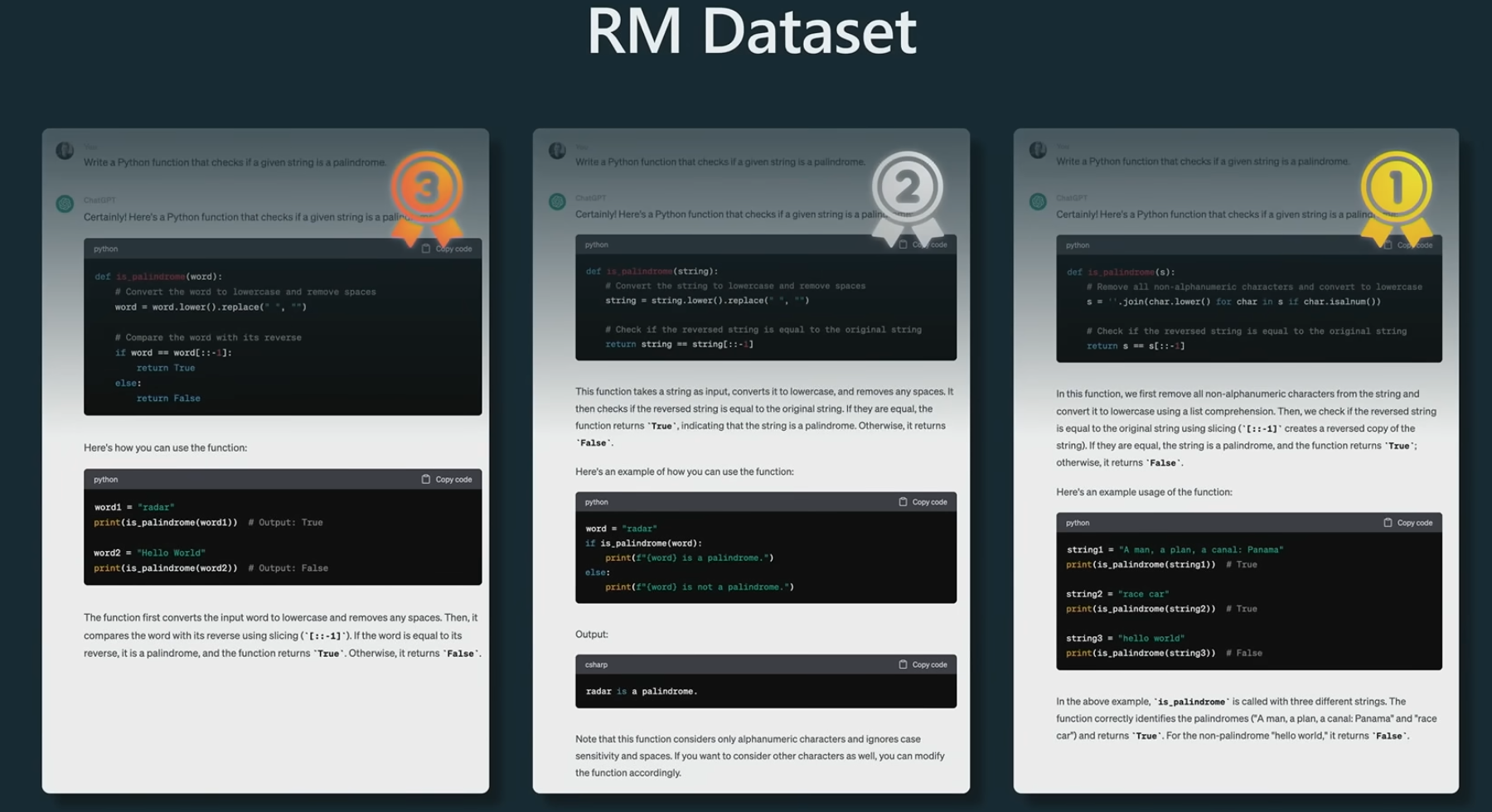
- 相同的prompt, SFT model 会给出不同版本的回答,即多个候选答案。目前我们在使用
- 人类评估者会对这些候选回答进行比较打分排名,并选择他们认为最合适或最准确的回答。
- 模型会根据这些比较结果进行学习,以便对其他问题的多个候选答案的好坏进行预测
3.1.2 RM Training

从图中可以看出, 提示词+ 结果+ 人类评估者反馈作为关联在一起的数据又被打包到batch中进行训练, 如图,可以理解成一个相同的提示词prompt 有3个不同版本的回答,对应的3个不同的reward(可以理解成是分数), 训练后模型就可以针对一个prompt 的回答预测出一个人类评估者的打分。
所以这个阶段的目的就是构建一个reward model 学习人类打分的规律,以来预测一个回答可能会获得的人类评分。
由于reward model只是学习了人类打分的规律,所以如果单独使用Reward Model 进行打分并不会促进模型生成更好的答案 , 它需要和Reinforcement Learning 强化学习结合使用才能起作用
3.2 Reinforcement Learning
有了reward model 后,就可以对模型的回答进行打分。对于分数高的回答,要提高其出现的概率,如此不断迭代,尽可能生成获得更高分的回答。