0. 项目结构介绍
| Module | Description |
|---|---|
| trustmessage-mysql | 基于2PC+MySQL表实现的可靠消息中心,业务操作+消息表操作均存在于同一个项目中 |
| turstmessage-middleware | 可靠消息中心中间件,基于RPC接口提交消息+2PC+MySQL 表实现 |
| turstmessage-middlewareapi | 可靠消息中心中间件, 回查接口定义 |
| Turstmessage-middlewareclient | 可靠消息中心中间件, 消息生产者,提供了HTTP回查接口、Dubbo泛化回查接口的示例 |
以下是项目正式介绍。
在业务处理中,经常会有重要但没那么紧急的数据需要同步给下游,比如
- 订单侧完成消息后给优惠侧发一个消息,优惠侧做一个单向对账的功能,确保券被正确核销
在这种场景中,需要把本地业务操作 + 消息发送当成一个事务处理,即满足原子性, 一般常见的解决方案会有两种
- 本地事务+本地消息表
- RocketMQ
本项目将从本地事务+本地消息表 出发, 一步步探讨如何用 MySQL 实现一个支持分布式事务的可靠消息中心,即TrustMessage。
1. 本地事务+ 本地消息表
由于Spring 的事务机制只保证数据库操作的原子性,所以当涉及到 数据库的业务操作 和 其他中间件如kafka操作 具有原子性的时候,就要用其他的方案来保证。
本地事务+ 本地消息表 这种方案是把 需要发送的消息作为数据库操作的一部分,保存到数据库中的一个表里,然后通过另外的逻辑,将消息的真正发送 稍后异步进行,比如用一个定时任务将消息异步发送到Kafka。
这种方法确保了数据库操作和消息发送在逻辑语义上的原子性,因为它们都在同一个数据库事务中处理。
这里需要注意,这种方案的实时性是比较差的,所以你需要判断的业务场景场景是否能够容忍这样的异步操作。
关于Spring事务,可以点击阅读Spring事务实现原理
1.1 业务流程
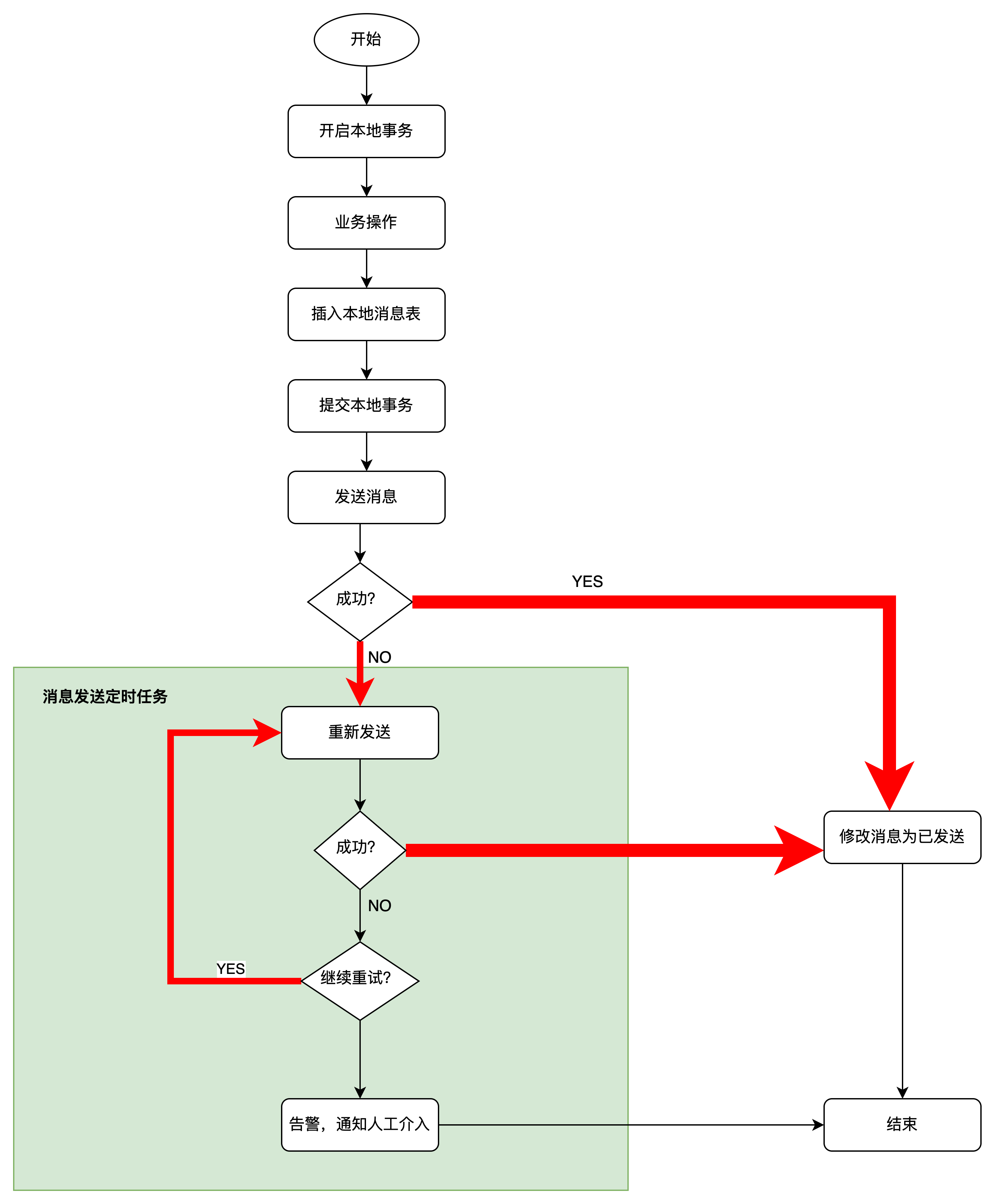
以上流程中,在本地事务提交后,有一个定时任务轮询消息表将需要发送的消息消息发送出去。有4个点需要注意一下
- 事务提交后了,消息发送失败, 定时任务的重试机制,会找出这条消息进行异步补发
- 事务提交后了,消息发送成功,但是消息状态修改状态, 定时任务会找出这条再次发送
- 重试异步补发过程中,如果消息依然发送失败,那么会继续重试补发
- 重试异步补发过程中,消息发送成功,但是数据库消息已发送状态修改失败,那么定时任务又会再次找到这条消息再发一遍
以上 2和4 均会面临消息重复的情况, 个人认为在业务常见中消息重复是一种可接受的情况,有时候业务自己甚至会消息重放, 所以消息消费者做好幂等逻辑就可以了。
1.2 消息发送重试次数
消息发送不能无限次重试
浪费资源,重试了那么多次都未成功,可能是逻辑出现问题了或者宕机了,赶紧去查问题吧
上下游业务数据迟迟无法达到最终一致性 , 本身我们使用消息其终极目的就是为了让系统数据达到最终一致性, 如果一直无限制发送,这个目的是无法达到的, 所以赶紧停下去查问题吧
基于以上两个考虑,系统对于重试都应该有个次数限制,达到次数限制后就应该告警让人工介入处理。
1.3 消息表设计
在本地事务+ 本地消息表 方案中,其消息表的设计一般如下,
1 | CREATE TABLE message ( |
2. 如果消息表和业务表操作是分布式事务
但是如果保证不了这两个表不在同一个库 /数据库实例中,那就会在业务操作和消息表写入两个操作中遇到分布式事务。这在分库分表的业务中是很容易出现的情况。
针对对分布式事务,常见的解决方案就是 2PC、3PC、TCC、SAGA。
接下来将讲解以 2PC+MySQL消息表 实现的可靠消息中心
2.1 业务流程
以MySQL消息表+ 2PC 来实现可靠消息中心, 其整体实现流程如下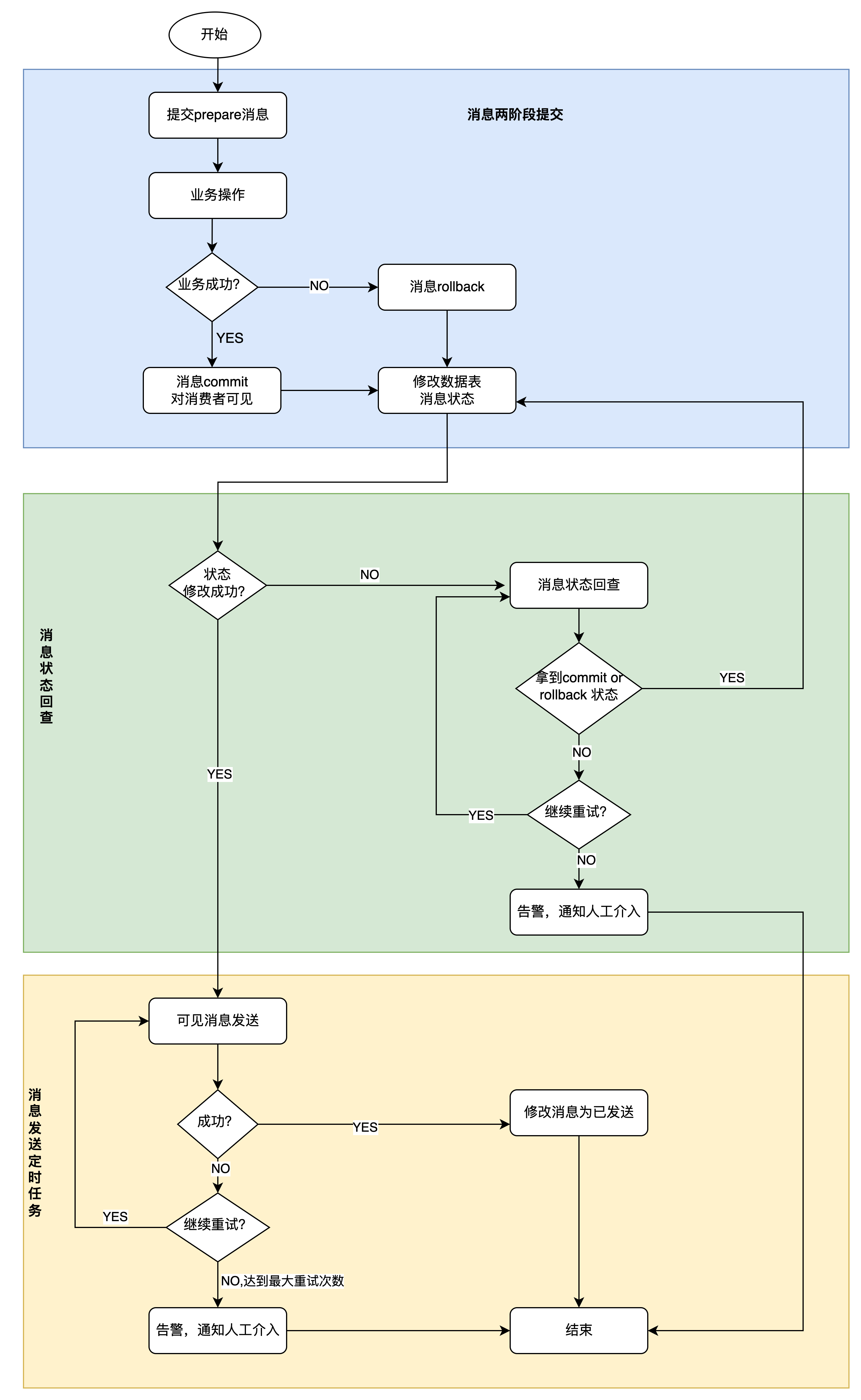
2.2 消息可见性
消息可见性, 在涉及分布式事务的场景中,消息增加了一个可见性概念, 这是因为在引入2PC 后,写入消息表的消息不再像本地事务+本地消息表一样写入即可见,必须是commit后才对消费者可见, 所以在数据表的设计中需要增加一个状态字段来维护消息可见性。1
message_status INT COMMENT '消息状态 1-prepare 2-commit 3-rollback 4-unknown',
其状态流转如图所示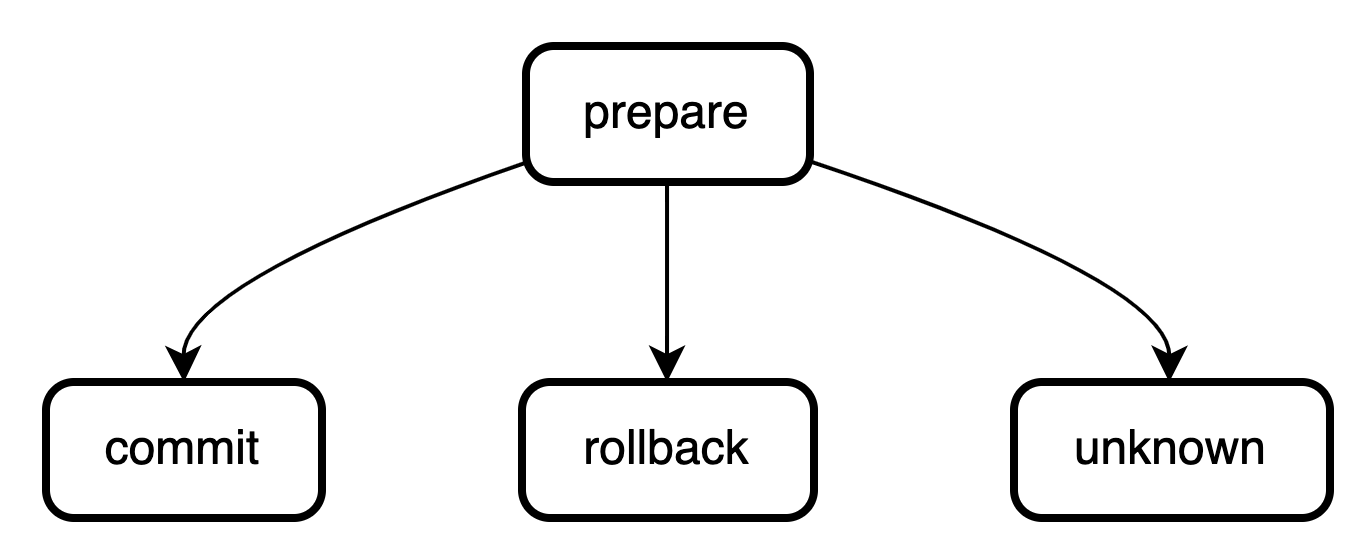
2.3 如果业务执行消息commit or rollback 失败怎么办-消息回查
如流程图中所示,在2PC 阶段,拿到业务执行结果修改消息状态失败有可能是失败。
一个操作执行失败后,一种常见的解决方案方案就是重试,尽最大努力交付。
但是对于业务处理来讲,一般有超时时间的限制,因为这种同步重试可能并不适用,即使可以,一般重试次数都会限定在3次。
除了同步重试,还有一种方案就是 消息回查,我个人理解这相当于一种异步重试。
在本项目中,消息回查指的就是开启一个定时任务去全表扫描,找出insert一定时间后,其状态仍然是 prepare的消息 ,通过业务逻辑判断该条消息是否已经执行完成 or 失败,对应地把消息状态更改为 commit or rollback。
为了进行消息回查,肯定要有一个业务唯一标识来识别该条消息需要对应业务数据,从而判断对应业务是否执行完成。1
message_key VARCHAR(255) COMMENT '消息唯一键,用于做回查的标识',
2.4 消息回查不能无限次
- 浪费资源,回查了这么多次的都没拿到结果,一种可能就是业务逻辑出现问题了,适可而止赶紧去查问题吧
- 系统数据迟迟无法达到最终一致性 , 本身我们使用消息其终极目的就是为了让系统数据达到最终一致性, 如果一直无限制查询,这个目的是无法达到的, 所以赶紧停下去查问题吧
所有消息回查应该有个次数限制, 这就是表中以下两个字段的作用1
2verify_try_count INT COMMENT '消息状态回查 下次重试次数',
verify_next_retry_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '消息状态回查 下次重试时间 1-未发送 2-已发送',
2.5 消息回查次数达到上限怎么办
有两种参考方案
- 默认修改消息状态为commit 或者 rollback,
- 将消息状态置为回查失败状态 , 告警人工介入处理
默认修改消息状态为commit 或者 rollback 这个方案,一个最大的问题就是针对状态不确定的消息,不论将其默认修改为那种状态, 都是有可能引起业务上下游数据不一致问题。
一旦上下游数据产生了数据不一致性,必然导致很长的排查链路和大量的数据修复工作。
所以本项目中我选择第二种方案,消息回查达到上限后直接告警,让消息生产者这一方人工介入处理。
此处说明一下,这种方案当然也会有数据不一致的问题,因为下游业务始终还未拿到消息修改自己的状态,但是相比拿到了随机确定的的状态 导致的数据不一致性,此时问题还被控制在消息生产者这一环,问题排查会相对简单。
2.6 消息发送重试
与本地事务+本地消息表方案一致
2.7 消息表设计
1 | CREATE TABLE message ( |
2.8 消费者消费消息
针对可见, 即已经commit 的消息,消费者该如何获取到消息消费呢,有两种方案
- 消息者直接查询消息表
- 消费者从消息队列队列消费
2.8.1 消息者轮训消息表
这种方案最大的问题就是,在微服务架构下,上下游两个不同的服务 操作 同一个数据表 是一个不合理且不推荐的做法。
2.8.2 消息队列消费
和本地事务+本地消息表一样,已经commit 的消息可以由一个定时任务轮训发送到业务创建的消息队列中供订阅的消费者消费
发送过程也可以有一个重试的过程。
3. 如果这是一个公共中间件-基于RPC 接口实现的可靠消息中心
以上讨论的方案, 都是基于消息表逻辑和业务逻辑同一个服务中, 如果把该功能做成一个公共中间件,那么在技术方案上会略有变化。
中间件需要提供的功能
- 两阶段提交功能
- 回查功能
- 消息转发
以上3个功能和上一种方案没有本质上的区别, 只是基于一个中间件的定位,支持这3种功能需要更多的封装与数据信息。
3.1 业务流程
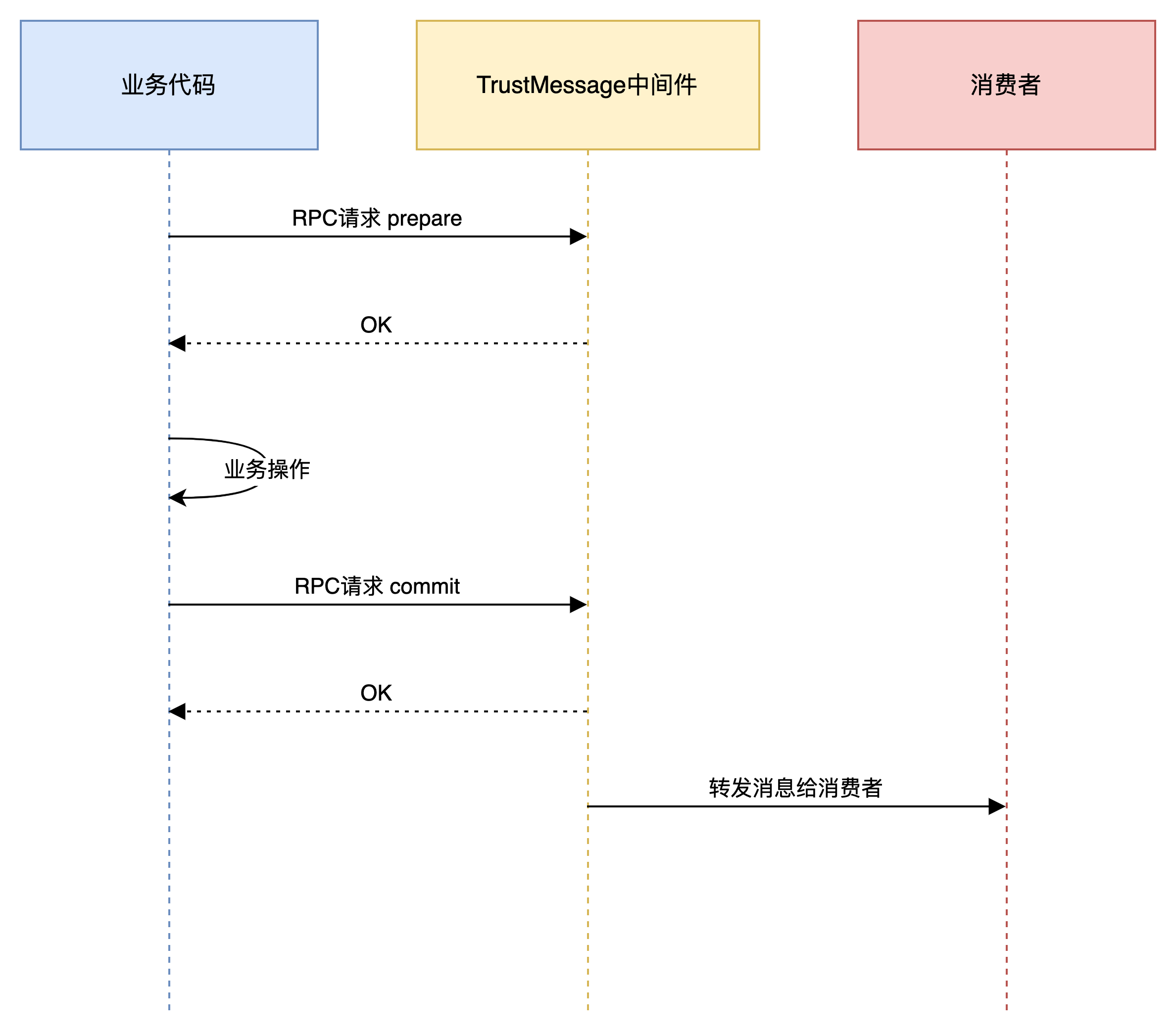
3.2 两阶段提交功能
提供3个RPC 接口, prepare, commit, rollback, 接口底层封装对数据表的操作
3.3 消息唯一性
当作为一个公共中间件,接受多个业务数据的时候,消息的唯一性应该有业务标识 + 消息标识共同确定,即bizId + messageKey
3.4 回查功能
相比于直接在业务服务里集成可靠消息的功能时,可以简单直接的在服务内部查询,当作为公共中间件时, 只能通过服务间调用完成,服务间调用有两种形式
- HTTP
- RPC
为了增加可维护性和拓展型, 无论是哪种形式,中间件都应该定义好调用的格式,让消息生产者按照统一格式提供回查接口。
这个格式包括
- 接口定义
- 接口入参
- 接口返回值
其中接口定义信息需要生产消息时提供
在实现消息生产者按照统一格式提供回查接口 这一点是,HTTP接口的回查相对简单, 如果RPC 接口, 要注意使用泛化调用。
本项目实现了HTTP 接口的回查和 Dubbo 协议的泛化调用回查
HTTP接口格式为1
http://127.0.0.1:8082/verifyMessage?bizID=1&messageKey=key1
Dubbo RPC 接口定义为1
2
3
4
5public interface VerifyMessageService {
// 消息回查接口
int verifyMessage(Integer bizID,String messageKey);
}
3.5 消息转发
在一个公共中间件里实现消息转发,必然也需要生产消息时提供这部分信息1
2forward_topic VARCHAR(255) COMMENT '业务转发topic',
forward_key VARCHAR(255) COMMENT '业务转发指定key',
3.6 消息表设计
1 | CREATE TABLE message ( |
4. 基于kafka 提交消息实现的可靠事件中心
在实现消息回查的可靠消息中心方案中,另外一种常见的方案是 业务代码直接把消息提交给kafka, 然后中间件消费消息并持久化道数据库中,等待消息提交commit 或者rollback , 没有的话就进行回查。如下图,图片源自极客时间专栏
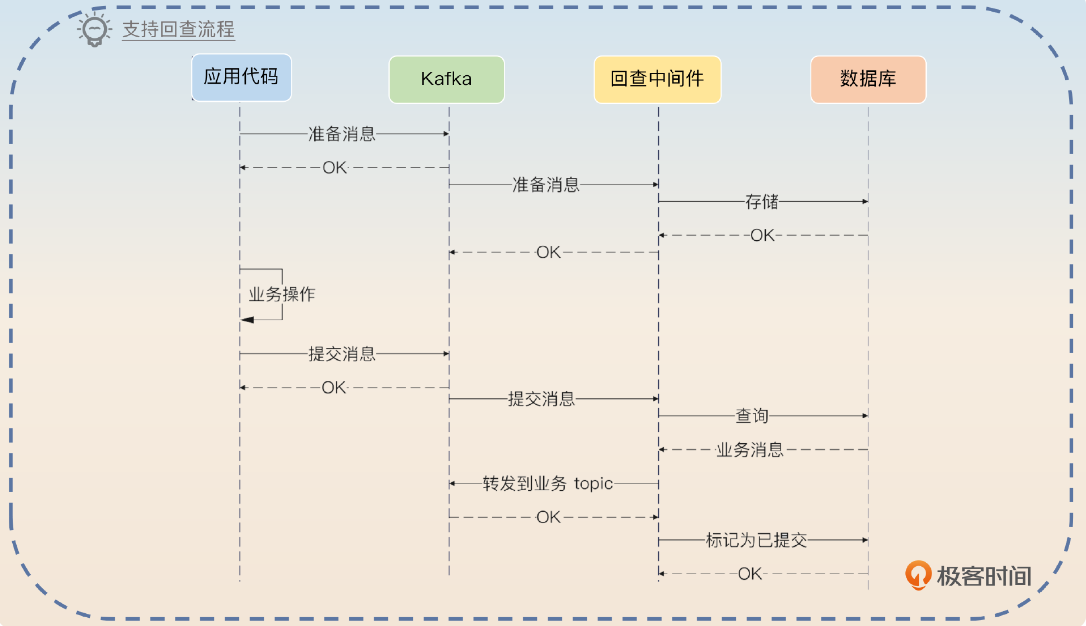
我认为两种技术方案没有本质的区别, 其差异只是消息的prepare 、commit、rollback 的提交是由RPC 接口完成还是由消息生产消费完成, 其他回查的逻辑、发送逻辑、以及需要的信息基本无差异。
不过在使用Kafka 提交时,有以下两种需要考虑
4.1 中间件如何识别一条消息是事务消息
- Topic命名约定
一种简单的方法是通过Topic命名来区分。例如,所有需要支持回查的Topic可以遵循一个特定的命名模式,如添加前缀或后缀(例如,replayable-myTopic)。这种方法的优点是简单易实施,但缺点是灵活性较低,且对现有系统可能需要更多的改动。
- 特定主题或分区
将需要回查的消息发送到Kafka的特定主题或分区中。这样,中间件只需监听这个特定的主题或分区来处理需要回查的消息。这种方法要求生产者在发送消息时知道哪些消息需要回查,并据此发送到正确的主题或分区。
- Topic配置属性
Kafka允许为每个Topic设置自定义配置属性。可以引入一个自定义属性(如replayable=true)来标识一个Topic需要支持消息回查。这种方式比命名约定更为灵活和隐蔽,但要求应用层和消息生产者遵循这一约定,并且需要在应用层实现逻辑来处理这些属性。
- 消息元数据标记
在消息发送时,可以在消息的元数据(Metadata)中添加特定的标记或字段来指示这条消息需要进行回查。
设计考虑:
- 性能:确定这些方法中哪一种对生产和消费的性能影响最小。
- 易用性:选择易于实施和维护的方法。
- 灵活性:评估是否需要对单个消息进行标记,还是以Topic为单位进行区分。
4.2 如何识别消息类型、转发信息、回查信息
消息类型包括 prepare、commit、rollback
转发信息,需要转发至的真正业务tpoic、 如果需要指定分区的话还包括key信息
回查信息,包括回查方式如HTTP、RPC, 回查地址,回查接口等
- 使用Kafka消息头
优点:
- 保持了消息体的纯净和独立性。
- 灵活性高,易于添加或修改额外的控制信息和元数据。
- 性能考虑,对于小到中等大小的消息,使用消息头的性能开销相对较小
缺点: - 新版本依赖:较旧版本的Kafka客户端可能不支持消息头功能,这要求生产者和消费者使用支持消息头的Kafka版本。
- 额外处理:消费者需要额外的步骤来读取和解析消息头。
- 预先定义消息格式
优点:
- 直接且简单,易于实现。
- 不依赖Kafka特定的功能,具有较好的兼容性。
缺点: - 增加了消息体的大小。
- 需要在消费端进行消息解析,略微增加了处理的复杂性。
本项目以指定topic+预定义消息格式的方式简单实现了消息的提交,消息格式如下, 大家可以参考。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28package com.example.trustmessage.middlewareapi.common;
public class MiddlewareMessage {
// 要给到业务方的真正消息
private String message;
private int bizID;
// 用于消息回查的业务唯一标识
private String messageKey;
private int messageStatus;
private String forwardTopic;
// 向业务方转发时需要指定的key,没有则说明按照kafka 默认分区策略进行分区
private String forwardKey;
private VerifyInfo verifyInfo;
public static class VerifyInfo {
private int protocolType; // 1-http, 2-rpc-dubbo
private String registryProtocol;
private String registryAddress;
private String url;
private String version;
}
}
5. 基于RPC接口 vs 基于Kafka提交
基于两种不同消息提交方式实现的中间件, 将从以下两方面进行比较
- 消息的顺序性
- 流量增加后扩容
5.1 消息的顺序性
使用中间件回查机制,由于网络原因,有可能出现 某条业务的commit or rollback 消息比prepare 先到达中间件,面对这种情况,commit or rollback的处理逻辑是需要报错的,client 只能重试或者等待回查机制更新消息状态
但是由于kafka 可以在一个分区内的保证消息的有序性,所以基于Kafka提交的方案可以有一种优雅的方式保证prepare消息和commit/rollback 消息的有序性。
解决方案很简单,生产者在发送消息按照业务 唯一标识指定key ,即指定目标分区即可。
5.2 流量增加后扩容
以下比较基于在代码层面已经做好分库分表、异步处理、批量处理、cache 等性能优化的基础上
假设已经分库分表,数据库处理不是瓶颈
万一流量激增,基于Kafka提交的方案 可能会产生产生必须要处理的消息积压,针对消息积压常见的解决方案中
- 增加消费者数量,不过一般来讲,线上生产环境都会已经把消费者数量和分区数量设置成一样的,所以这个方案无法发挥功能
- 增加分区数量,假设公司的工作流程里允许增加,如果使用场景对消息顺序性有要求,你又要考虑新增分区后对消息顺序性的影响
- 新建一个更多分区的topic, 涉及到生产者、消费者的代码变更
- 消费者性能优化, 比如异步处理、批量处理, 但是如果项目已经做好这些措施,面对消息积压,只能回到下面3种方式
综合以上,我个人认为基于RPC接口的方案可以用自动扩容策略直接应对, 简单直接优雅。
6. 作为中间件的技术设计
6.1 性能提升
- 线程池异步处理
- cache 存储回查接口
- 基于bizID + messageKey 的分库分表
6.2 幂等性
- prepare 消息的幂等性, 唯一索引