在Intro to 事务中介绍过, 一致性是事务的核心特征,或者说最终目的,原子性、隔离性和持久性都是实现一致性的手段。
所以在介绍InnoDB 事务时,主要介绍AID 特性的实现
InnoDB事务-原子性的实现, undo log
InnoDB事务-隔离性的实现, MVCC & 锁
InnoDB事务-持久性的实现, binglog & redo log&undo log
在具体看InnoDB 事务实现AID 特性之前,可以先看以下这些前置知识
1. InnoDB 数据管理
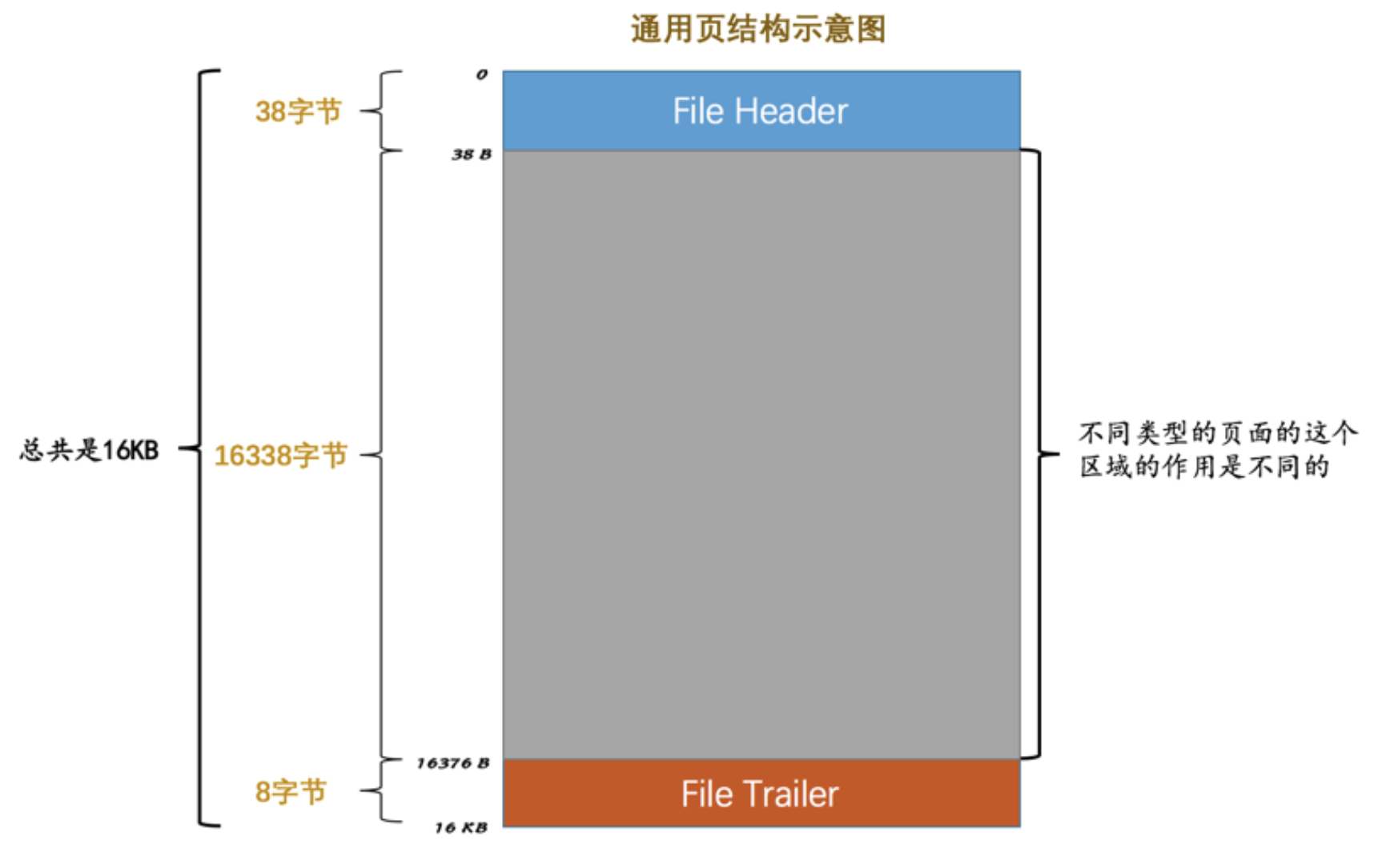
1.1 Page
page 是 InnoDB 存储数据的基本单位,也是数据在磁盘和内存之间交换的最小单位。每个页通常的大小为 16KB
针对不同的数据有不同的Page类型进行存储,如index page 索引页, undo page 等
- File Header 中 有fil_page_type 来标识该页的类型
- File Trailer 用来校验页面数据是否完成

1.2 区(extent)
为了更好地管理page, InnoDB引入了区的概念, 连续的64个page 是一个区,大小默认是1MB。 可以认为extent 是一个物理上概念
一个区(Extent)是由连续的页组成的数据块,每个区包含 64 个连续的页,因此每个区的大小为 1MB (16KB * 64)。使用区的目的是为了优化磁盘空间的分配和管理,通过批量处理连续的页,减少随机IO来提高数据存取效率。
1.3 段 (segment )
InnoDB 中的段(Segment)作为一个逻辑结构,起着将数据库的高层逻辑结构(如表和索引)与低层物理存储结构(如页和区)连接起来的桥梁作用。
以下是几个详细的例子,通过这些例子可以更好地理解段是如何在数据库管理系统中发挥作用的。
1.3.1 数据表段
假设您在数据库中创建了一个新表,这个表将需要存储数据行。InnoDB 会为这个表创建一个数据段:
- 逻辑层面:在逻辑层面,这个数据段代表了表中所有数据行的集合。
- 物理层面:物理上,这个数据段开始时可能只包含几个区,每个区由 64 个连续的页组成。随着表中数据的增加,段可以动态地分配更多的区来存储更多的数据页。
- 操作:当你执行 INSERT 操作向表中添加数据时,InnoDB 将在这个数据段中找到适当的页来存储新的行。如果必要的页不存在或页已满,段管理逻辑将请求分配新的区,并继续数据插入。
1.3.2 索引段
当你为表创建一个索引时,无论是主键索引还是辅助索引,InnoDB 都会为每个索引创建一个单独的索引段:
- 逻辑层面:索引段逻辑上表示索引的结构,这包括维护键值和指向表中对应行的指针。
- 物理层面:物理上,索引段存储索引树(B-tree)的结构,其中每个节点(或页)包含索引键和指向行的指针。随着索引的增长,可能需要更多的页和区来扩展索引树。
- 操作:进行查询优化时,如执行基于索引的查找,InnoDB 通过索引段快速访问相关页,有效地定位到数据行。
1.3.3 Undo 日志段
Undo 日志也是使用段来管理的,每当数据被修改时,修改前的数据将存储在 undo 日志段中:
- 逻辑层面:逻辑上,undo 日志段保存了数据修改前的状态,支持事务的回滚操作。
- 物理层面:物理上,undo 日志段由一系列的页组成,这些页按需分配,并在事务回滚时提供必要的历史数据。
- 操作:如果事务失败或执行 ROLLBACK 命令,InnoDB 通过访问 undo 日志段中的记录来恢复数据到其原始状态。
1.4 表空间(Tablespace)
表空间是 InnoDB 数据存储的最高层级,它可以包含多个段。表空间是磁盘上的物理文件,可以看作是一个容器,内部组织着数据库的数据和索引。InnoDB 默认有一个主表空间,即 ibdata 文件,它包含了系统数据、数据字典、undo 日志等。此外,InnoDB 还支持每个表使用单独的文件作为独立表空间(file-per-table),这有助于数据库的扩展和管理。
2.行记录格式
数据表中的行存放在 数据page 中, 以compact 行格式为例, 每一条数据记录的存储格式如下,
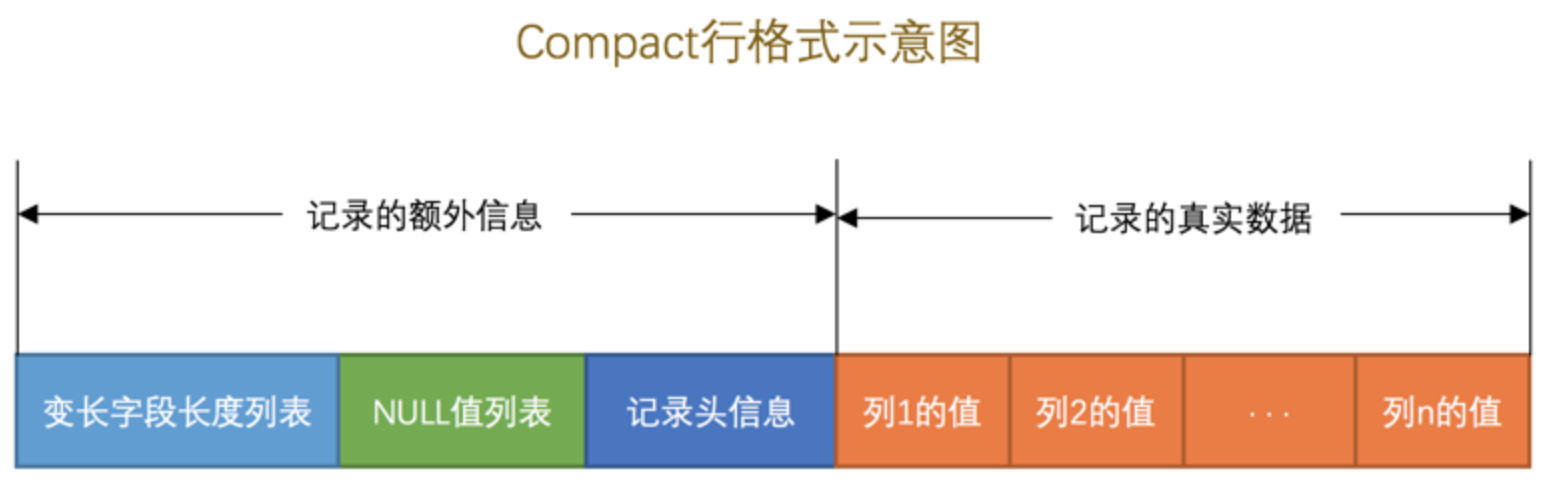
其中真实数据部分,除了数据表中定义的列之外,InnoDB 会默认为每条记录添加隐藏列
| 列名 | 是否必须 | 占据空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6 字节 | 行ID,唯一标识一条记录 |
| trx_id | 是 | 6 字节 | 事务ID |
| roll_pointer | 是 | 7 字节 | 回滚指针 |

roll_pointer 是存储在每个行记录中的一个指针,指向该行记录相关的最近一次undo log 记录。trx_id 是 InnoDB 存储引擎内部用来唯一标识每个事务的标识符,它记录了最近修改该记录的事务。
3. InnoDB 事务trx_id
trx_id 是 InnoDB 存储引擎内部用来唯一标识每个事务的标识符。这个事务ID是一个递增的数字,由 InnoDB 内部自动生成和管理。
trx_id 存储在行记录的隐藏列中。
MySQLserver 层也有一个事务唯一标识叫XID。
InnoDB 内部维护了一个 max_trx_id 全局变量,每次需要申请一个新的 trx_id 时,就获得 max_trx_id 的当前值,然后并将 max_trx_id 加 1。
功能和作用
- 事务的唯一标识:
trx_id为 InnoDB 提供了一种方式来唯一地识别和跟踪每个活动的或已完成的事务。 - 多版本并发控制(MVCC):在 InnoDB 的 MVCC 实现中,
trx_id被用来标记每条记录的版本,以此来支持事务的隔离级别。不同事务看到的数据视图依赖于记录的trx_id与事务的trx_id比较。 - 回滚和恢复:在事务处理过程中,如果需要回滚,InnoDB 通过
trx_id来确定哪些更改需要被撤销。此外,在系统崩溃后的恢复过程中,trx_id也被用来重建活跃事务的状态。