在以上2篇文章中,已经详细说明了
- 本地事务下通过数据库乐观锁、数据库悲观锁、分布式锁 实现安全扣减库存
- 分布式事务下,通过预扣库存方案 实现安全扣减库存
以上所有方案,其处理逻辑均依赖于数据库, 在高并发场景下会遇到 DB 层面带来的性能瓶颈。
面对数据库带来的性能瓶颈问题,最简单直接且有效的方法就是就是升级数据库硬件配置以提高性能,唯一的问题就是费钱。
如果不升级数据库配置,但又想提升性能,通常考虑以下2种常见方案
- Redis 扣减库存
- 库存分段
这2种方案虽然花的钱少了, 但是处理逻辑逻辑变得更复杂了。
下面将对这2种方案进行详细解释。
1. Redis 扣减库存
在高并发场景下,直接依赖数据库进行库存扣减会因数据库性能受限,导致每个请求都需要先查询库存是否充足。这不仅增加了数据库的压力,还使得抢不到库存的用户需要等待较长时间,带来了不必要的延迟。
通过引入 Redis 进行库存扣减,可以显著提升处理效率。作为内存级数据库,Redis 能够快速判断库存是否足够。
整体处理流程如下
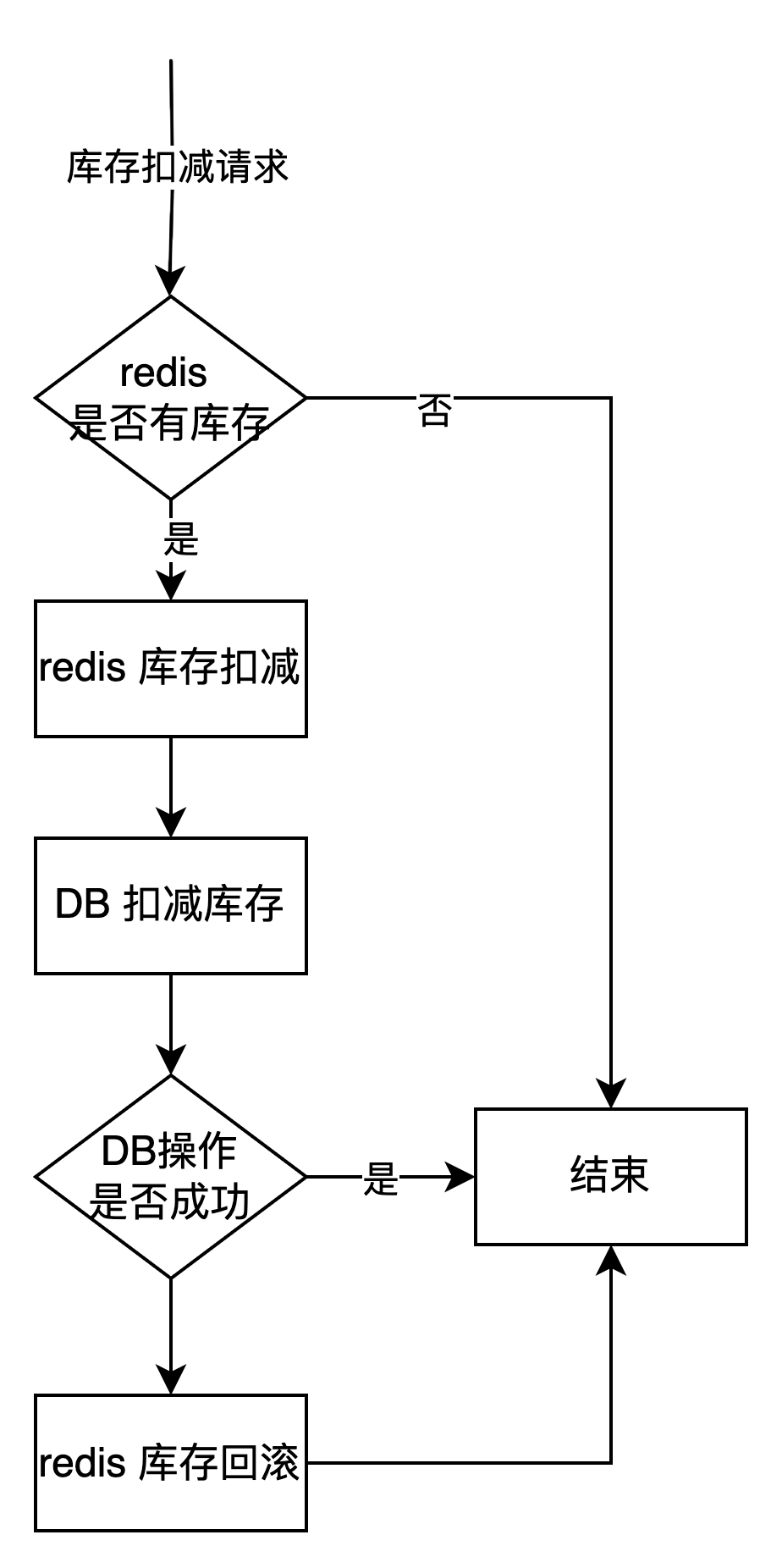
- 如果 Redis 中有库存,扣减后放行请求,继续进行数据库层面的库存扣减和订单生成等业务逻辑。
- 如果 Redis 中没有库存,则直接返回“库存已抢完”的提示,用户无需再等待,从而大幅缩短未抢到库存用户的响应时间。
方案优点:
- 提高并发处理能力:通过 Redis 的内存操作,系统可以在高并发环境下快速响应库存请求。
- 减少数据库压力:仅有成功抢到库存的请求才会访问数据库,未抢到库存的请求会在 Redis 阶段直接返回,减少无效的数据库操作。
- 缩短响应时间:未抢到库存的用户会立即得到反馈,不需要等待长时间的数据库查询,显著提升用户体验。
1.1 Redis库存从哪来-库存预热
在服务启动时,应该将库存预加载到 Redis 中,以确保高并发情况下的快速响应。
对于分布式部署的服务,多个实例可能同时尝试加载库存。为了避免重复预热或数据不一致,需要加锁机制(如 Redis 分布式锁)来确保只有一个服务器负责执行库存预热操作,其他服务器等待预热完成后使用 Redis 中的数据。
当然还有一种情况是 库存模版创建时进行同步
1.2 Redis库存扣减逻辑
在使用Redis 扣减库存时,要判断库存是否足够然后才能够进行扣减, 需要用Lua 脚本保证Redis 操作间的完整性。1
2
3
4
5
6
7
8
9
10
11
12
13String luaScript =
"local current_stock = tonumber(redis.call('GET', KEYS[1])) " +
"local deduct_amount = tonumber(ARGV[1]) " +
"if current_stock == nil then " +
" return -2 " +
"elseif current_stock == 0 then " +
" return 0 " +
"elseif current_stock < deduct_amount then " +
" return -1 " +
"else " +
" redis.call('DECRBY', KEYS[1], deduct_amount) " +
" return 1 " +
"end";
lua 脚本的返回值有一下4种情况
- -2 代表Redis 库存不存在, 有可能是服务预热缓存逻辑出了问题
- -1 当前有库存,但是库存不足以支持当前请求
- 0 Redis 库存存在,但是已经被扣减完, 无法支持此次库存扣减请求
- 1 库存扣减成功
1.3 DB 扣减库存
在 Redis 扣减库存成功后,继续在DB层 执行库存扣减,并确保数据库扣减操作尽可能成功,以避免触发 Redis 库存的回滚。
在DB层扣减库存可以使用select ... for update 数据库悲观锁
1.4 DB 扣减库存失败怎么办-Redis 库存回滚
数据库扣减库存失败后,需要将 Redis 中扣减的库存加回去,以保证 Redis 库存与数据库库存的数据一致性
但是,Redis 库存回滚操作有失败的可能性,如果失败了,有2种方案应对
- 重试
- 定时任务刷新库存。该定时任务可以周期性地将数据库的库存状态同步到 Redis中,确保数据一致性
2. 库存分段
redis扣减库存有一个问题,它适合库存较少的业务场景, 比如10瓶茅台,20个戴森吹风机,100个iphone手机。
但是如果库存较多,比如2000, 那么在高并发情况下,就会有2000个请求在Redis 扣减成功后同时来到DB层面。 这就会造成一行数据库热点数据的情况, 在使用 select ... for update 执行数据库库存扣减时,大量事务将处于等待状态,依然会遇到性能问题。
面对库存较多,又是热点数据的情况, 解决方案就是库存分段。
库存分段就是将大库存拆分成多个较小的库存段,每个库存段独立维护库存值。
当有商品销售请求时,可以按照路由规则将请求分配到一个库存分段,而不是对整个库存进行锁定操作。这样可以分散并发请求到不同的库存段,从而减少锁的粒度,提升系统的并发处理能力。
2.1 表设计
既要有库存表,存储库存配置时的基本信息,又要有一个库存分段表存储每个段负责的库存量并负责实际的库存扣减工作。
- inventory 表相比之前设计的方案,少了承载库存扣减功能的available_stock字段,只有始终不变的total_stock字段,那是因为实际库存扣减放在了inventory_segment表中
1 | CREATE TABLE inventory ( |
1 | CREATE TABLE inventory_segment ( |
product_id:表明该库存分段属于哪个产品。segment_id:用于标识该产品的第几个库存段,结合product_id可以唯一标识某个产品的某个库存分段。total_stock:该分段的总库存,可以根据业务需求按比例分配。available_stock:该分段的当前可用库存,用于在实际销售中进行扣减。version:乐观锁控制字段,防止并发扣减时出现库存超卖的情况。status:分段库存的状态UNIQUE KEY:product_id和segment_id共同作为唯一键,保证每个产品的每个库存分段都是唯一的。
3. 使用库存分段需要考虑的3个问题
使用库存分段技术, 需要考虑以下问题
- 分段配置策略:如何合理设置分段数量与每个分段的库存分配
- 分段路由规则:库存扣减请求到来时,如何制定高效的分段选择规则,以减少碎片化并提升操作效率?库存扣减请求到来时, 选择哪个库存处理请求
- 如果选择的一个分段不够请求扣减数量怎么办
- 分段配置策略:如何合理设置分段数量与每个分段的库存分配。合理的分段配置策略可以平衡系统的性能、复杂性与库存利用率
- 分段路由规则:库存扣减请求到来时,如何选择处理请求的分段。合理的分段路由规则应该是尽可能减少碎片化并提升操作效率
- 分段不足处理逻辑:当选定的分段库存不足时,如何处理该请求
以上3个问题问题,在不同的业务场景下有不同的处理方案。
不同的业务场景可以概括为2种
- 每次请求扣减数量固定。比如经典的秒杀场景, 默认用户只能购买一个。
- 每次请求扣减数量不固定。比如每次购物节抢购时,有很多人同时抢,商品库存量比秒杀场景大,且不限制只能抢一个
3.1 分段配置策略
3.1.1 分段库存固定
事先确定好每个分段的库存数量, 根据配置的总库存即可直接计算出分段数量。
在扣减数量固定 的业务场景下实现简单且维护成本低,是很实用的方案。
3.1.2 动态分段
动态分段策略在初期**先以固定分段为基础,然后在库存实际使用过程中,根据库存消耗情况和业务需求进行动态调整。
动态调整的过程涉及到分段合并、分段分裂2种情况。
在请求扣减数量不固定业务场景下, 当选中的分段不不足以支撑扣减时,就需要对分段进行合并。
这增加了实现和维护的复杂度。在调整分段时可能需要锁定部分库存分段,对高并发的扣减操作会有一定影响。
分段路由规则和分段策略应该配套使用,比如按照范围分段则路由请求时就要按照范围大小选择
3.1.3 库存分段的插入
- 注意要使用数据库事务来保证库存表和库存分段表的数据插入操作的原子性
- segment_id, 如果你事先决定了每个产品有固定数量的库存段,可以简单地按照顺序分配
segment_id1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public void createInventoryWithSegments(int productId, int totalStock) {
// 计算分段数量
int segmentCount = (int) Math.ceil((double) totalStock / SEGMENT_STOCK);
// 插入主库存记录
InventoryModel inventory = new InventoryModel();
inventory.setProductId(productId);
inventory.setTotalStock(totalStock);
inventory.setAvailableStock(totalStock);
inventoryMapper.insertInventory(inventory); // 保存主库存记录
// 准备插入分段记录
List<InventorySegmentModel> segments = new ArrayList<>();
for (int i = 1; i <= segmentCount; i++) {
int stockForSegment = Math.min(SEGMENT_STOCK, totalStock); // 最后一段可能不足segmentStock
totalStock -= stockForSegment; // 减去已分配给段的库存
InventorySegmentModel segment = new InventorySegmentModel();
segment.setProductId(productId);
segment.setSegmentId(i);
segment.setTotalStock(stockForSegment);
segment.setAvailableStock(stockForSegment);
segments.add(segment);
}
// 插入所有分段库存
inventorySegmentMapper.batchInsert(segments);
}
3.2 分段路由规则
库存扣减请求到来时,如何选择处理请求的分段。
路由规则的设计会影响系统的性能、库存利用率和处理高并发请求时的稳定性。
路由规则可以是随机、轮询、顺序使用或者根据某些业务规则进行选择。每种策略都有其适用的场景。
常见的分段选择策略
- 随机选择分段, 实现简单,如果随机选择到的分段库存不足,需多次重试,这会增加请求耗时,尤其是在库存接近耗尽的情况下。
- 全局轮询选择分段,通过一个全局轮询的索引,记录当前分配到的分段索引,以便每个请求可以按顺序逐段轮询。
- 按顺序使用分段库存,当一个分段用完后再按照顺序使用下一个分段,而不是从每个请求重新计算应该使用的分段。这样可以确保系统在使用库存时保持连续性,避免频繁从头开始查找,提高整体效率。
- 基于库存量的优先选择策略,比如每次请求优先选择库存最大库存段进行扣减,实现稍复杂,需要对库存进行比较和排序。
3.3 分段不足处理逻辑
一般来讲, 在扣减数量固定 的业务场景下,分段配置策略选择分段库存固定,并将每个分段的库存设置为固定扣减数量的倍数, 分段路由规则不论选择哪种, 那么理论上分段库存要么是0 不足以扣减, 如果有库存就一定能扣减。所以在遇到库存为0的情况,换一个分段就可以了。
因此重点考虑在扣减数量不固定业务场景下的分段不足问题。
比如当前有以下分段
分段1, 可用库存2
分段2, 可用库存3
分段3,可用库存1
此时过来一个请求扣减4, 此时不论选择哪个分段,分段库存都是不够的,但是当前总库存是足以支持该请求的,面对这种请求有以下处理方案
- 直接返回库存不足,请求处理失败,即使总库存足够
- 总库存足够,就要处理请求,处理逻辑有以下情况
- 依次在多个分段中扣减库存,直到扣减的库存数量满足要求
- 对当前可用库存重新分配,重分配后有一个分段可以满足要求
4. 扣减数量固定-按顺序使用分段库存
当一个分段用完后,再按照顺序使用下一个分段,而不是在每次请求时重新从第一个分段开始计算。这样可以确保系统在使用库存时保持连续性,避免频繁从头开始查找,提高整体效率。
4.1 Redis存储当前活跃库存分段
可以使用Redis 存储当前扣减到的库存段,每个扣减请求到来时,直接从Redis 中读取当前活跃库存段进行扣减。
1 | "activeSegmentInfo:1001" = { |
4.2 库存数据预热
在服务启动时,将库存相关数据加载到Redis 中
关于预热逻辑的多服务器并发问题,可以Redis分布式锁解决
4.3 更新Redis 库存分段-版本号防止并发修改覆盖
修改Redis 中活跃分段信息时, 虽然Redis 天然可以支持并发,但是应用程度把命令通过网络传输给redis 服务器的时候,有可能发生并发覆盖更新的情况,所以在更新数据时可以使用版本号解决这个问题。
由于版本号在数据库中无任何对应数据, 所以可以使用时间戳作为版本号,每次更新数据时, 时间戳都必须大于Redis 中存储的时间戳版本号才能修改数据
4.4 库存分段用完标识
如果所有库存分段的数据用完,可以在Redis 中添加一个特殊值,进行标识。
如果用完, 则每个库存扣减请求不需要再请求数据库判断是否还能扣减请求
5. 扣减数量不固定
前面我们说了,当扣减数量不固定时,需要处理的最复杂的问题就是分段不足的情况
比如当前有以下分段
分段1, 可用库存2
分段2, 可用库存3
分段3,可用库存1
此时过来一个请求扣减4, 此时不论选择哪个分段,分段库存都是不够的,但是当前总库存是足以支持该请求的,面对这种请求有以下处理方案
- 直接返回库存不足,请求处理失败,即使总库存足够
- 总库存足够,就要处理请求,处理逻辑有以下情况
- 跨分段扣减:依次在多个分段中扣减库存,直到扣减的库存数量满足要求
- 分段合并:对当前可用库存重新分配,重分配后有一个分段可以满足要求
本文以下内容重点讨论分段合并的分析与实现。
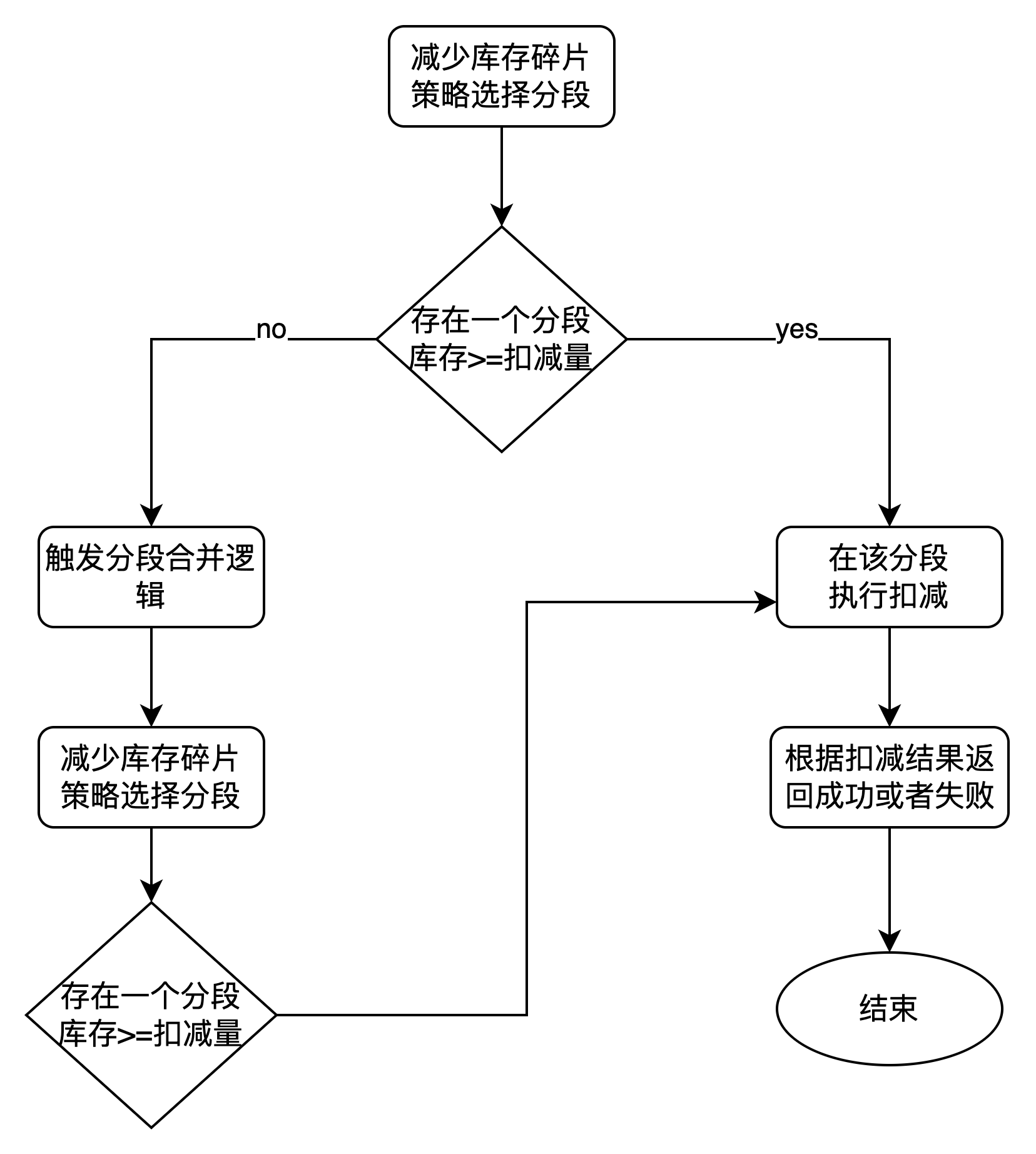
5.1 分段路由规则-减少库存碎片
最佳实践-减少库存碎片。
对于扣减数量不固定的场景,分段选择策略应该以尽可能减少库存碎片,以尽可能减少触发库存合并逻辑为原则。
可以采取的匹配策略 时
- 优先选择库存刚好等于需求量的分段
- 其次选择库存略大于等于需求量的分段
5.2 分段合并逻辑
目前有2个时机会触发分段合并逻辑
- 定时任务, 分段碎片化程度达到标准即执行分段合并逻辑
- 没有分段能够处理请求,但是总库存足够的情况下,执行分段合并逻辑
分段合并时如何生成新分段有2种思路
- 和分段最初创建时的逻辑保持一致, 计算当前所有可用库存,把之前的分段全部设置成不可用的状态,根据每个分段的固定库存量, 生成该商品下的新分段。 在定时任务触发分段合并逻辑时,可以使用这种逻辑
- 如果请求扣减库存的数量 大于分段固定的库存量,那么就不能使用第一种思路了,否则产生的新分段还是不能满足扣减请求,因此先产生一个能够满足扣减请求的分段,如果还有剩余库存,再按照第一种思路生成新分段。
分段合并的并发执行
要确保在任意时刻只有一个线程能够执行分段合并逻辑,否则可能会发生数据不一致的情况
在分段合并执行时,该productId 对应的所有的分段逻辑应该全部锁住,不能再执行扣减逻辑, 否则可能会发生数据不一致的情况。 这种情况会影响库存扣减请求的处理性能。
6 控制数据层并发数
一般来讲,多线程相比单线程而言可以提高性能, 但是线程过多反而会适得其反。
所以可以通过压测得出一行热点数据并发的最高性能。然后将业务请求按照商品ID 分类排序后按照顺序并发到到数据库层面进行处理。